Random encoders for sentence classification
🐱 Codificadores aleatorios para embeddings de oraciones


Charla basada en este paper:
https://arxiv.org/pdf/1901.10444.pdf
A complex pattern-classification problem, cast in a high-dimensional space nonlinearly, is more likely to be linearly separable than in a low-dimensional space, provided that the space is not densely populated.
— Cover, T. M.
Aproximaciones no supervisadas basadas en la hipótesis distribucional: palabras que ocurren en el mismo contexto tienden a tener significados similares.
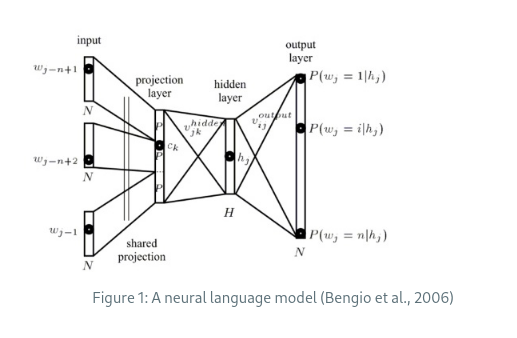
Word embeddings pre-entrenados:
- word2vec
- GloVe
- fastText
- ELMo
La intención es usar un clasificador sobre los embeddings de documentos (downstream task).

O simplemente una medida de similaridad.
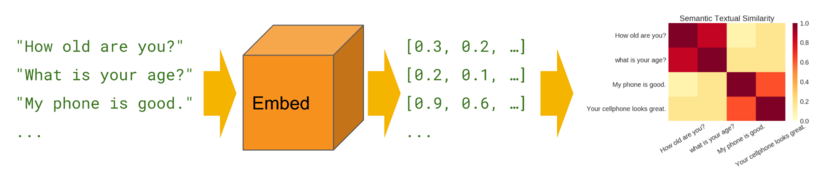
Tareas y datasets
https://arxiv.org/pdf/1705.02364.pdf
Clasificación
- sentiment analysis (MR, SST),
- product reviews (CR),
- subjectivity (SUBJ),
- opinion polarity (MPQA),
- question-type (TREC).

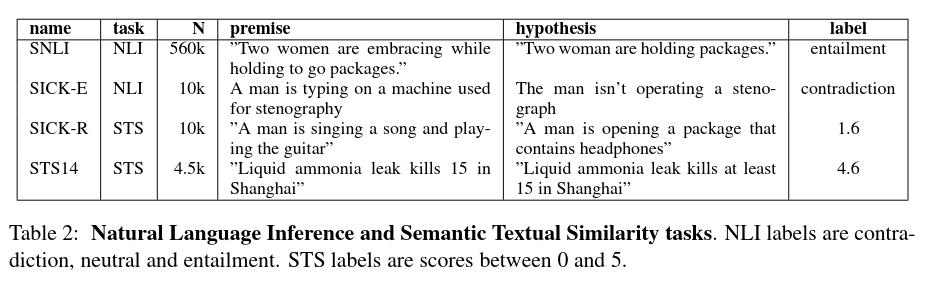
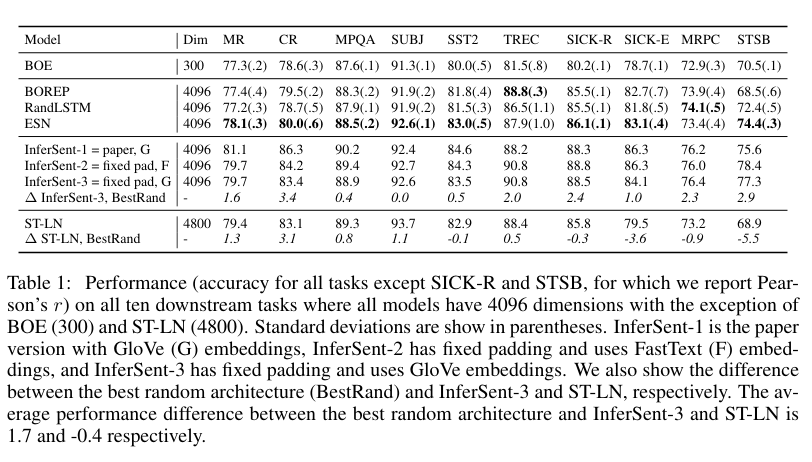
Encoders entrenados
$h = f_θ(e_1, \ldots, e_n)$
- Interesa obtener una representación $h$ de una oración,
- usando alguna función $f$ parametrizada por $θ$,
- en función de embeddings pre-entrenados $e$ donde $e_i$ es la representación de la i-ésima palabra en una oración de largo $n$.
Típicamente los codificadores aprenden $θ$, parámetros que luego se mantien fijos en las tareas de transferencia.
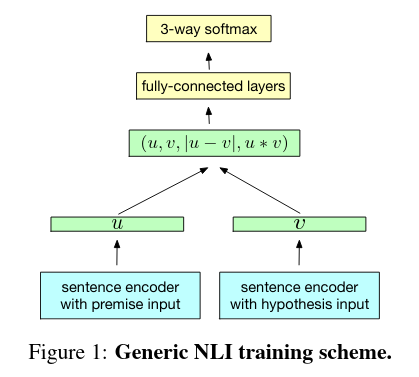
InferSent
https://arxiv.org/abs/1705.02364
Supervisado usando el corpus Stanford Natural Language Inference (SNLI). Requiere una gran cantidad de anotaciones.
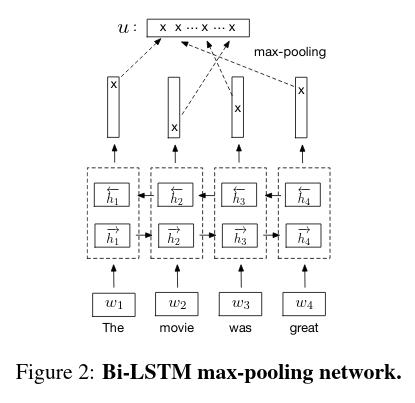
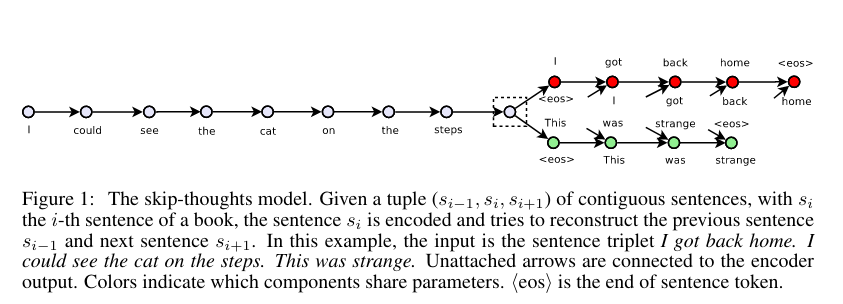
Skip-Thought
https://arxiv.org/abs/1506.06726
No supervisado. En vez de predecir las palabras que envuelven a una palabra (skip-gram), predice las oraciones alrededor de una oración dada. Entrenarlo lleva un tiempo muy largo.
$h = f_{\text{pool}}(X W)$
- $W ∈ \mathbb{R}^{D×d}$ se inicializa al azar usando una distribución uniforme entre $[\frac{−1}{\sqrt{d}}, \frac{1}{\sqrt{d}}]$.
- $D$ es la dimensión de los word embeddings, $d$ es la dimensión de la proyección.
- $f_{\text{pool}} = \text{max}$ (max pooling) o $f_{\text{pool}} = \text{mean}$ (mean pooling).
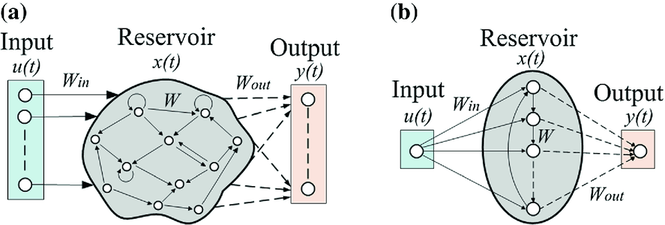
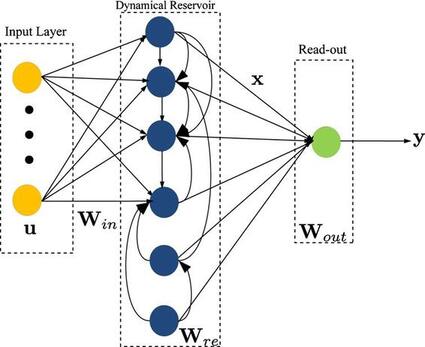
$(\hat y_1, \ldots, \hat y_n) = \text{ESN}(e_1, \ldots, e_n)$
Descripción formal de una ESN:
$\tilde h_i = f_{\text{act}} (W^i e_i + W^h h_{i−1} + b^i)$
$h_i = (1−α) h_{i−1} + α \tilde h_i$
- $W^i$, $W^h$, $b^i$ son inicializados al azar y no se actualizan durante el entrenamiento.
- $α ∈ (0,1]$ es el grado de mezcla entre el estado previo y el actual.
$\hat y_i = W^o [e_i;h_i] + b^o$
- $W^o$, $b^o$ son los únicos parametros que se entrenan.
- $\hat y_i$ es la predicción para $y_i$.
- NO SE USA.
$h = f_{\text{pool}}(\text{BiESN}(e_1, \ldots, e_n))$
- Se utiliza una ESN bidireccional, los estados del reservorio de ambas direcciones se concatenan $h_i = [\overrightarrow{h_i};\overleftarrow{h_i}]$.
- Mediante pooling de estos estados se obtiene la representación de la oración $h$.
La echo state property clama que el estado del reservorio debe ser únicamente determinada por la historia de entrada y que los efectos de un estado dado deben disminuir en favor de estados más recientes. En la práctica esta propiedad se satisface asegurando que el valor absoluto del autovalor más grande de $W^h$ sea menor que 1.
Parte 2: Código (BOREP)
Vamos a intentar la estrategia de bag of random embeddings projection.
https://github.com/dair-ai/emotion_dataset
sadness 😢
joy 😃
love 🥰
anger 😡
fear 😱
surprise 😯import pandas as pd
pd.set_option('max_colwidth', 400)
df = pd.read_pickle('datasets/emotions.pkl')
df.emotions.value_counts()
for emotion in df.emotions.unique():
sample = df.query(f'emotions == @emotion').sample(5)
print(emotion.upper())
for _, text in sample.text.items():
print('* ' + text)
print('\n')
Revisando las muestras nos damos cuentas de que es un dataset bastante polémico.
docs = [doc.split() for doc in df.text]
docs[3]
import numpy as np
from itertools import chain
from collections import Counter
import torch
from tqdm import tqdm
class Vocab():
@property
def índice_relleno(self):
return self.mapeo.get(self.tóken_relleno)
def __init__(self, tóken_desconocido='<unk>', tóken_relleno='<pad>', frecuencia_mínima=0.0, frecuencia_máxima=1.0,
longitud_mínima=1, longitud_máxima=np.inf, stop_words=[], límite_vocabulario=None):
self.tóken_desconocido = tóken_desconocido
self.tóken_relleno = tóken_relleno
self.frecuencia_mínima = frecuencia_mínima
self.frecuencia_máxima = frecuencia_máxima
self.longitud_mínima = longitud_mínima
self.longitud_máxima = longitud_máxima
self.stop_words = stop_words
self.límite_vocabulario = límite_vocabulario
def reducir_vocabulario(self, lote):
contador_absoluto = Counter(chain(*lote))
contador_documentos = Counter()
for doc in lote:
contador_documentos.update(set(doc))
# frecuencia mínima
if isinstance(self.frecuencia_mínima, int): # frecuencia de tóken
vocabulario_mín = [tóken for tóken, frecuencia in contador_absoluto.most_common() if frecuencia >= self.frecuencia_mínima]
else: # frecuencia de documento
vocabulario_mín = [tóken for tóken, frecuencia in contador_documentos.most_common() if frecuencia/len(lote) >= self.frecuencia_mínima]
# frecuencia máxima
if isinstance(self.frecuencia_máxima, int): # frecuencia de tóken
vocabulario_máx = [tóken for tóken, frecuencia in contador_absoluto.most_common() if self.frecuencia_máxima >= frecuencia]
else: # frecuencia de documento
vocabulario_máx = [tóken for tóken, frecuencia in contador_documentos.most_common() if self.frecuencia_máxima >= frecuencia/len(lote)]
# intersección de vocabulario_mín y vocabulario_máx preservando el órden
if len(vocabulario_mín) == len(vocabulario_máx):
vocabulario = vocabulario_mín
else:
vocabulario = [tóken for tóken in tqdm(vocabulario_mín, 'Procesando documentos') if tóken in vocabulario_máx]
# longitud
vocabulario = [tóken for tóken in vocabulario if self.longitud_máxima >= len(tóken) >= self.longitud_mínima]
# stop words
vocabulario = [tóken for tóken in vocabulario if tóken not in self.stop_words]
# límite
vocabulario = vocabulario[:self.límite_vocabulario]
return vocabulario
def fit(self, lote):
vocabulario = []
if self.tóken_relleno:
vocabulario.append(self.tóken_relleno)
if self.tóken_desconocido:
vocabulario.append(self.tóken_desconocido)
vocabulario += self.reducir_vocabulario(lote)
self.mapeo = {tóken: índice for índice, tóken in enumerate(vocabulario)}
return self
def transform(self, lote):
if self.tóken_desconocido: # reemplazar
return [[tóken if tóken in self.mapeo else self.tóken_desconocido for tóken in doc] for doc in lote]
else: # ignorar
return [[tóken for tóken in doc if tóken in self.mapeo] for doc in lote]
def tókenes_a_índices(self, lote):
lote = self.transform(lote)
return [[self.mapeo[tóken] for tóken in doc] for doc in lote]
def índices_a_tókenes(self, lote):
mapeo_inverso = list(self.mapeo.keys())
return [[mapeo_inverso[índice] for índice in doc] for doc in lote]
def __len__(self):
return len(self.mapeo)
@property
def vocabulario(self):
return list(v.mapeo.keys())
def obtener_embeddings(self, fastText):
embeddings = [
fastText[tóken] for tóken in self.vocabulario
if tóken not in (self.tóken_desconocido, self.tóken_relleno)
]
embeddings = torch.stack( list( map(torch.tensor, embeddings) ) )
if self.tóken_desconocido:
unk = embeddings.mean(dim=0, keepdim=True)
embeddings = torch.cat([unk, embeddings])
if self.tóken_relleno:
pad = torch.zeros(1, fastText.get_dimension())
embeddings = torch.cat([pad, embeddings])
return embeddings
v = Vocab(tóken_desconocido=None, tóken_relleno=None)
v.fit(docs)
len(v)
v.tókenes_a_índices([['i', 'was', 'feeling', 'a', 'little', 'low', 'few', 'days', 'back']])
import fasttext
import fasttext.util
fasttext.util.download_model('en', if_exists='ignore')
ft = fasttext.load_model('cc.en.300.bin')
e = v.obtener_embeddings(ft)
e.shape
idxs = v.tókenes_a_índices(docs)
x = e[ idxs[3] ]
x.shape
D = 300
d = 512
w = torch.empty(D, d)
w = torch.nn.init.uniform_(w, -1/np.sqrt(d), 1/np.sqrt(d))
w.shape
xw = torch.mm(x, w)
xw.shape
xw.max(dim=0).values.shape
s = torch.stack( [ torch.mm(e[doc], w).max(dim=0).values for doc in tqdm(idxs) ] )
emo = [
['sadness'],
['joy'],
['love'],
['anger'],
['fear'],
['surprise'],
]
emo_idxs = v.tókenes_a_índices(emo)
emo_sents = [ torch.mm(e[doc], w).max(dim=0).values for doc in emo_idxs ]
d = torch.nn.PairwiseDistance(p=.5)
d(emo_sents[0].reshape(1,-1), emo_sents[1].reshape(1,-1))
dist = torch.stack( [d(s, sent) for sent in tqdm(emo_sents)], dim=1 )
dist.shape
y_pred = dist.min(dim=1).indices
labels = {
'sadness':0,
'joy':1,
'love':2,
'anger':3,
'fear':4,
'surprise':5,
}
df['y_true'] = df.emotions.map(labels)
from sklearn.metrics import classification_report
print(classification_report(df.y_true, y_pred, target_names=labels))
Muy tristes estos resultados 😢. Quizás random sentence encoders funcione más para entrenar clasificadores más que para medidas de similaridad.
x.max(dim=0).values.shape
s = torch.stack( [ e[doc].max(dim=0).values for doc in tqdm(idxs) ] )
emo_sents = [ e[doc].max(dim=0).values for doc in emo_idxs ]
dist = torch.stack( [d(s, sent) for sent in tqdm(emo_sents)], dim=1 )
dist.shape
y_pred = dist.min(dim=1).indices
print(classification_report(df.y_true, y_pred, target_names=labels))
Embedding a embbeding
Dado que la estrategia anterior no funcionó, veamos qué sucede con la más clásica todavía comparación palabra a palabra usando embeddings de palabras sin proyección. Vamos a comparar cada palabra del documento con la palabra de emoción y nos quedaremos con la distancia más corta para determinar la distancia del documento a la emoción.
dist = []
for sent in emo_sents:
# distancia de cada embedding (tóken) del documento a la emoción
distancias_docs = [ d(e[doc], sent).min() for doc in idxs]
dist.append( torch.stack( distancias_docs ) )
dist = torch.stack(dist, dim=1)
dist.shape
y_pred = dist.min(dim=1).indices
print(classification_report(df.y_true, y_pred, target_names=labels))