Un recorrido por scikit-learn
៱˳_˳៱∫ Una visita guiada por la guía de usuarie de la librería


- Requisitos
- Utilidad
- Datos
- Objetos
- Flujo de trabajo
- Datos
- Limpieza de datos
- Partición del conjunto de datos
- Transformadores: preprocesamiento de atributos
- Estimadores: selección de modelos
- Evaluación del modelo
- Flujo de datos
- Pipeline
- Optimización: validación cruzada
- Optimización: búsqueda
- Evaluación final
- Persistencia del modelo
- Extra: Muestreo — conjunto desbalanceado
- Ejercicio: Boston price data set
- Automatización
Preparé unas clases introductorias a la librería de aprendizaje automático scikit-learn. Las notas de las clases, que aquí comparto, si bien no llegan a conformar un tutorial, perfilan como una guía para recorrer la documentación de la librería en gran parte de su extensión.
En esencia reorganicé las guías de usuario de la librería en torno al flujo de trabajo del desarrollo de modelos. Adicionalmente, como en la vida real los datos de los que uno suele disponer están lejos de ser perfectos, añadí algunas técnicas para trabajar con conjuntos de datos desbalanceados.
- Recorrido por las posibilidades de la librería (guías de usuario)
- Familizarización con la documentación (API)
- Tarea: implementación de un flujo de trabajo sencillo para regresión (parecido al tutorial básico)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sn
Requisitos
Algo de familiaridad con NumPy. Ver este tutorial.
Utilidad
- Aprendizaje supervisado
- Clasificación
- Regresión
- Aprendizaje no supervisado
Aprendizaje por refuerzos
Redes neuronales: solo perceptrón multicapa y restricted Boltzmann machine.
Datos
scikit-learn consume datos con forma de matriz o arreglo bidimensional, de dimensión (n_muestras, n_atributos) — es como imaginamos normalmente a los datos, dispuestos en una tabla donde las columnas son los atributos y hay tantas muestras como filas.
Convencionalmente en la documentación la varible X se utiliza para los atributos propiamente dichos, y la variable y para los objetivos. Cuando el objetivo es uno solo, y suele tomar la forma de arreglo unidimensional de dimensión (n_muestras,).
Objetos
En scikit-learn hay dos tipos fundamentales de objetos:
-
Los transformadores, que implementan los métodos
-
fit(X, y)y -
transform(X),
-
-
y los estimadores, que implementan
-
fit(X, y), -
predict(X).
-
Datos
Vamos a usar el conjunto de datos de plantas de iris para los ejemplos. Este dataset es una especie de hola mundo del aprendizaje de máquinas.

Cantidad de instancias: 150
Atributos (4)
1. Largo del sépalo [cm]
2. Ancho del sépalo [cm]
3. Largo del pétalo [cm]
4. Ancho del pétalo [cm]
Objetivos (1)
5. Clase
- Setosa
- Versicolour
- Virginica
Valores ausentes: No
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
print('X: datos ', X.shape)
print('y: objetivo', y.shape)
Limpieza de datos
https://en.wikipedia.org/wiki/Data_cleansing
- Cardinalidad
- Rango
- Desviación
- Tipo
- Booleano
- Numéro (separadores)
- Texto
- espacios (trimming)
- tildes
- casos (mayúsculas, minúsculas)
- Codificación (UTF-8, etcétera)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
Transformación
- Estandarización (
StandardScaler) — A cada atributo le remueve su valor medio y lo escala dividiéndolo por su desviación estándar.- Centrar los datos es prácticamente obligatorio (hay excepciones).
- Normalizar los datos solo si los atributos difieren en unidades y/u órdenes de magnitud.
- Reajuste
- Rango (
MinMaxScaler) - Valor absoluto (
MaxAbsScaler)
- Rango (
Ejemplo: StandardScaler
from sklearn.preprocessing import StandardScaler
std = StandardScaler(with_mean=True, with_std=True)
std.fit(X_train)
X_train_std = std.transform(X_train)
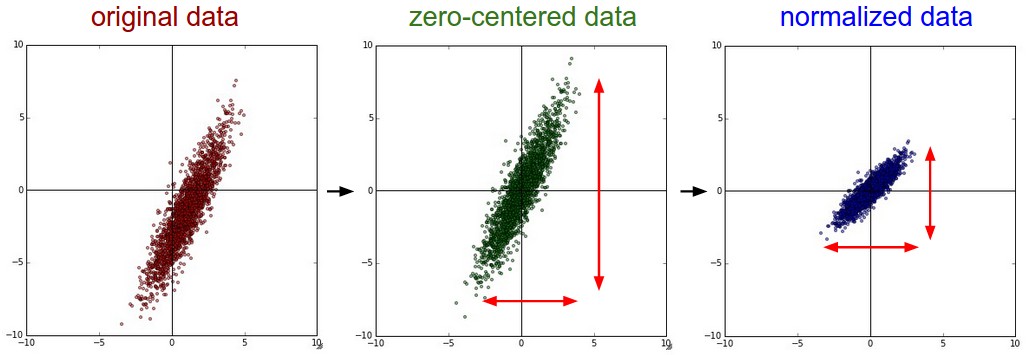
http://scikit-learn.org/stable/modules/preprocessing.html#normalization
- Normalización (Normalizer) — Divide vectores por su norma (afecta filas en vez de columnas).
Imputación de valores ausentes
http://scikit-learn.org/stable/modules/preprocessing.html#imputation-of-missing-values
- Descarte (tirar la muestra)
- Valor más común
- Valor medio
- Valor mediano
- Estimación (clasificación/regresión)
- Hot-deck (el valor de la muestra más parecida)
- Valor ausente (NA) como otro valor
Creación
http://scikit-learn.org/stable/modules/preprocessing.html#generating-polynomial-features
De $(X_1, X_2)$ a $(1, X_1, X_2, X_1^2, X_1X_2, X_2^2)$.
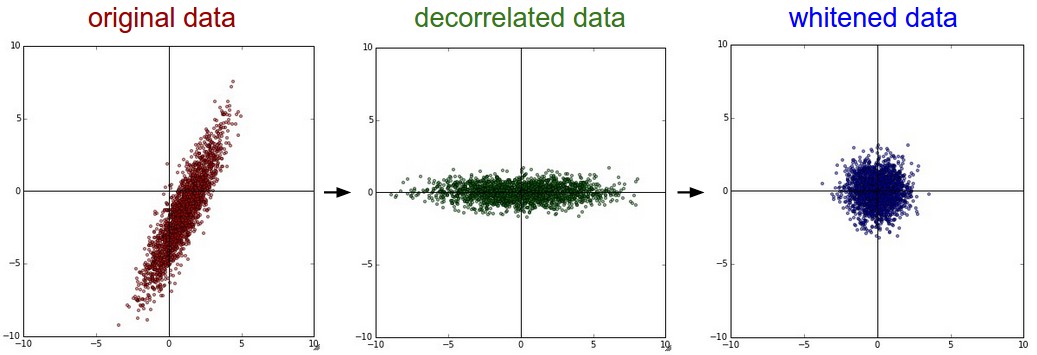
Reducción de dimensionalidad
http://scikit-learn.org/stable/modules/unsupervised_reduction.html
- PCA — análisis de componentes principales. Estandarizar los datos antes de usar PCA.
- Casi todos los estimadores no supervisados implementan el método
transform(X). - Algunos estimadores supervisados también.
Ejemplo: PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2, whiten=False)
pca.fit(X_train_std)
X_train_pca = pca.transform(X_train_std)
Selección — solo aprendizaje supervisado
http://scikit-learn.org/stable/modules/feature_selection.html
- Umbral de varianza
- Análisis univariado
- Usando un estimador
- Eliminación recursiva (también existe la agregación recursiva)
Ejemplo: SelectKBest
from sklearn.feature_selection import SelectKBest
kbest = SelectKBest(k=1)
kbest.fit(X_train_std, y_train)
X_train_kbest = kbest.transform(X_train_std)

¿Qué estimador usar para el conjunto de datos de plantas de iris?
- ¿Más de 50 muestras? Sí, el conjunto de datos tiene 150 (en realidad un poco menos porque hemos separado un conjunto de prueba).
- ¿Hay que predecir una categoría? Sí, queremos predecir a qué especie pertenece cada planta.
- ¿Los datos estás anotados? Sí, están anotados en tres categorías.
- ¿Más de 100,000 muestras? No...
Nos recomiendan usar una máquina de vectores de soporte (support vector machine) con un kernel lineal.
Ejemplo: SVC
from sklearn.svm import SVC
estimador = SVC(kernel='linear', C=1, probability=True)
estimador.fit(X_train_std, y_train)
X_test_std = std.transform(X_test)
y_pred = estimador.predict(X_test_std)
predict_proba(X)
http://scikit-learn.org/stable/modules/calibration.html
Al realizar la clasificación, a menudo se desea no solo predecir la etiqueta de la clase, sino también obtener una probabilidad de la etiqueta. Esta probabilidad da algún tipo de confianza en la predicción. Algunos modelos pueden darle estimaciones pobres de las probabilidades de la clase y algunos incluso no admiten la predicción de probabilidad. El módulo de calibración le permite calibrar mejor las probabilidades de un modelo determinado o agregar soporte para la predicción de probabilidad.
estimador.predict_proba(X_test[:3]).round()
Cantidad de objetivos — solo aprendizaje supervisado
http://scikit-learn.org/stable/modules/multiclass.html
- Clasificador
- Binario
- Multi
- Clase
- Etiqueta
- Clase-etiqueta
- Regresor
- Univariado
- Multivariado
En scikit-learn todos los clasificadores aceptan varias clases. Algunos estimadores trabajan inherentemente con múltiples objetivos y le sacan provecho a la correlación entre los mismos. Cuando no es el caso del estimador, existen diferentes estrategias para que admita múltiples objetivos:
- OVO (uno-contra-uno),
- OVA (uno-contra-todos).
Ensambles — solo aprendizaje supervisado
http://scikit-learn.org/stable/modules/ensemble.html
Diferentes tipos de ensambles:
- Promediadores: estimadores en paralelo, reducen la varianza.
- Propulsores (boosting): estimadores en serie, reducen el sesgo.
Evaluación del modelo
http://scikit-learn.org/stable/modules/model_evaluation.html
Cada estimador implementa un método llamado score(X, y) que devuelve un puntaje del desempeño del estimador. El puntaje es calculado usando una métrica acorde a la naturaleza del estimador, por ejemplo los regresores suelen reportar R² mientas que los clasificadores, efectividad.
estimador.score(X_test_std, y_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)
from sklearn.metrics import classification_report
clases = ['Setosa', 'Versicolour', 'Virginica']
print(classification_report(y_test, y_pred, target_names=clases))
F1
Útil para conjuntos de datos desbalanceados.
$F_1 = 2 \cdot \frac{\mathrm{precision} \cdot \mathrm{recall}}{\mathrm{precision} + \mathrm{recall}}$
from sklearn.metrics import f1_score
f1_score(y_test, y_pred, average='weighted')
Kappa de Cohen
https://en.wikipedia.org/wiki/Cohen's_kappa
Útil para conjuntos de datos desbalanceados.
$\kappa = \frac{p_o - p_e}{1 - p_e}$
from sklearn.metrics import cohen_kappa_score
cohen_kappa_score(y_test, y_pred)
Pipeline
http://scikit-learn.org/stable/modules/pipeline.html
Todos los objetos del flujo, excepto el último, deben ser muestreadores/transformadores (deben implementar el método sample/transform). El último objeto puede ser de cualquier tipo, suele ser un estimador.
Prestar atención a ColumnTransformer que permite aplicar transformadores a DataFrames de Pandas.
from sklearn.pipeline import make_pipeline
flujo = make_pipeline(StandardScaler(), SVC())
flujo.fit(X_train, y_train)
flujo.score(X_test, y_test)
Optimización: validación cruzada
http://scikit-learn.org/stable/modules/cross_validation.html
El conjunto de datos de validación sirve para ajustar a los hiperparámetros de los objetos que componen el flujo de trabajo, tanto como para la composición del flujo en sí mismo. La validación cruzada es útil cuando el conjunto de validación es necesario y las muestras son escasas.
Se necesitan dos cosas:
- Una estrategia de particionamiento de los datos.
- Una métrica de evaluación.
Estrategias
- K-fold, stratified k-fold — estrategias por defecto para regresores y clasificadores respectivamente.
- Leave one out (LOO)
- Leave P out (LPO)
- Shuffle & split, stratified shuffle & split
Métricas
- De no especificarse ninguna, se usa el método
score(X, y)del estimador. - Las métricas más comunes se pueden pasar como argumento (string), ver tabla.
- Se pueden armar puntuadores a partir de cualquier métrica, tanto de la API como definidas por el usuario, y pasar como argumento (función).
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
from sklearn.model_selection import cross_val_score
resultados = cross_val_score(flujo, X_train, y_train, cv=5, scoring='f1_weighted')
print('F1 promedio: %0.2f (+/- %0.2f)' % (resultados.mean(), resultados.std() * 2))
from sklearn.model_selection import GridSearchCV
hiperparámetros = {
'svc__kernel':('linear', 'rbf'),
'svc__C':[1, 10]
}
grilla = GridSearchCV(flujo, hiperparámetros)
grilla.fit(X_train, y_train)
estimador = grilla.best_estimator_
Evaluación final
Una vez elegido el modelo y ajustados sus hiperparámetros, si se desea los conjuntos de datos de entrenamiento y de validación pueden fusionarse en un nuevo conjunto de entrenamiento para reentrenar el modelo final usando más datos — de hecho es lo que hace GridSearchCV para el mejor estimador.
En cambio por más seguridad que se tenga del desempeño del modelo, no es recomendable usar los datos del conjunto de prueba, es mejor usarlos para medir su desempeño y asegurarnos de que esté libre de errores.
y_pred = estimador.predict(X_test)
f1_score(y_test, y_pred, average='weighted')
Persistencia del modelo
http://scikit-learn.org/stable/modules/model_persistence.html
import pickle
# persistencia
with open('modelo.pickle', 'wb') as archivo:
pickle.dump(estimador, archivo)
# carga
with open('modelo.pickle', 'rb') as archivo:
estimador = pickle.load(archivo)
Extra: Muestreo — conjunto desbalanceado
El entrenamiento y la validación de estimadores suele requerir conjuntos de datos balanceados; no así la prueba de los mismos ya que deben enfrentar datos reales del problema (desbalanceados).
scikit-learn apenas provee algoritmos de muestro, podemos usar la extensión imbalanced-learn que implementa varios.
pip install imbalanced-learn
imbalanced-learn aporta objetos del tipo muestreador (sampler) que implementan los métodos
-
fit(X, y)y -
sample(X, y).
Algunos algoritmos:
- Under-sampling
- ClusterCentroids
- RandomUnderSampler
- Over-sampling
- SMOTE
- RandomOverSampler
Nota: imbalanced-learn re-implementa la clase Pipeline para que admita muestreadores.
Ejemplo: RandomUnderSampler
from sklearn.datasets import make_classification
from imblearn.under_sampling import RandomUnderSampler
# generación de un conjunto de datos
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=200, random_state=10)
# aplicación de random under-sampling
rus = RandomUnderSampler()
X_resampled, y_resampled = rus.fit_sample(X, y)
Ejercicio: Boston price data set
Cantidad de instancias: 506
Atributos (13)
1. CRIM per capita crime rate by town
2. ZN proportion of residential land zoned for lots over 25,000 sq.ft.
3. INDUS proportion of non-retail business acres per town
4. CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
5. NOX nitric oxides concentration (parts per 10 million)
6. RM average number of rooms per dwelling
7. AGE proportion of owner-occupied units built prior to 1940
8. DIS weighted distances to five Boston employment centres
9. RAD index of accessibility to radial highways
10. TAX full-value property-tax rate per 10,000 USD
11. PTRATIO pupil-teacher ratio by town
12. B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
13. LSTAT % lower status of the population
Objetivos (1)
14. MEDV Median value of owner-occupied homes in 1000’s USD
Valores ausentes: No
from sklearn.datasets import load_boston
boston = load_boston()
X, y = boston.data, boston.target
print('X: datos ', X.shape)
print('y: objetivo', y.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
Sugerencias:
- 1.1 Modelo lineal
- 1.1.1. Ordinary least squares
- 1.1.2. Ridge regression
- 1.1.3. Lasso
from sklearn.metrics import r2_score
r2_score(y_test, y_pred) # mientras más cerca de 1.0, mejor
Automatización
TPOT es una herramienta de aprendizaje automático automatizado que optimiza el flujo de trabajo.
pip install tpot
from tpot import TPOTRegressor
tpot = TPOTRegressor(generations=3, population_size=20, verbosity=2)
tpot.fit(X_train, y_train)
y_pred = tpot.predict(X_test)
from sklearn.metrics import r2_score
r2_score(y_test, y_pred) # mientras más cerca de 1.0, mejor
tpot.export('tpot_boston_pipeline.py')